
리스닝마인드의 이용자라면 누구나 성별 및 연령별로 많이 검색되는 키워드와 토픽에 대한 정보를 확인 할 수 있는데요. 이를 가능하게 하는 기본 데이터는 전체 검색의 약 6할을 차지하는 네이버가 제공하는 검색 키워드별 성별, 연령별 검색 비율 정보 데이터입니다.
물론 단순한 비율 정보만으로는 성별 연령별 검색 특성을 파악할 수 없기 때문에 리스닝마인드는 실제 연령별 성별 인구구성 분포 실 데이터를 기준으로 표준편차 1 시그마 이상인 경우를 특정 성별, 연령별 특성이 나타나는 키워드로 분류하는 등의 별도의 데이터 분석 작업을 수행하고 있습니다. 이런 과정을 통해서 리스닝마인드의 이용자들은 자신이 알고 싶은 분야에 대한 소비자 검색 동향을 성별과 연령별로 나누어 보다 정확하게 파악할 수 있습니다.
리스닝마인드의 이용자들은 각 화면에서 확인한 검색 키워드들의 최근 2년간의 성별 및 연령별 월간 검색량을 엑셀파일 형태로 다운로드 받아 확인할 수 있습니다.
어떤 경우에 데모그래픽 정보를 수집하는 게 좋은가요?
특정한 토픽이나 특정한 키워드의 검색 이용자의 최근월 검색량이나 일정 기간 동안의 월별 검색량 변동을 분석하는 것만으로도 우리는 아주 다양한 인사이트를 얻을 수 있습니다. 그러나 이렇게 전체 연령층을 하나의 집단으로 보고 통합 분석하는 것으로는 실제 시장에서 일어나는 변화의 핵심을 놓칠 수 있습니다. 당연하지만 전 연령층이 동시에 동일한 방향으로 움직였을 가능성은 극히 낮기 때문입니다. 이럴 때에는 검색데이터를 데모그래픽 정보를 기준으로 나누어 분석을 수행해보는 것이 유의미할 수 있습니다.
특정 토픽의 검색량, 특정 브랜드의 검색량, 특정 의도를 가진 그룹의 검색량을 연령 혹은 성별로 세분화하하여 분석하면 시장에서 어떤 변화가 일어나고 있는 지를 깊이 있게 파악할 수 있습니다. 이러한 데모그래픽 세분화를 통한 검색량 분석에서는 특정 세그먼트에 관련된 전체 키워드를 파악한 상태에서 이들 키워드의 전체 검색량을 아는 것이 중요합니다. 그래야만 각 키워드나 토픽들이 가지는 절대 검색량이 가지는 의미를 이해할 수 있기 때문입니다.
일반적으로 다음과 같은 경우에 데모그래픽 정보를 기준으로 검색데이터를 분석하는 것이 도움이 됩니다.
- 시장 세분화와 타겟 세그멘트 확정: 특정 연령대나 특정 성별의 검색 패턴을 이해하여, 집중해야할 타겟 고객 그룹을 정하고 이에 맞춘 마케팅 전략을 수립할 때.
- 제품 개발 및 서비스 개선: 다양한 사용자 그룹의 니즈와 관심사를 확인하여 이를 제품이나 서비스 개선에 반영하고자 할 때.
- 시장 트렌드 분석: 특정 연령대나 성별의 중장기적 트렌드 및 단기 트렌드를 분석하여, 검색 패턴에 기반한 시장 변화를 예측하고 전략을 수립할 때.
이를 위해 필요한 전제는 분야를 포괄할 수 있는 충분한 키워드의 확보와 이들 키워드 전체에 대한 검색량 확보입니다. 충분한 키워드와 이들에 대한 검색량 정보가 충분하지 않으면 연령 및 성별로 세분화한 데이터의 신뢰성이 급격하게 떨어질 수 있습니다. 결과적으로 인사이트 도출이 어려울 수 있기 습니다. 따라서, 충분한 검색어 데이터를 확보하는 노력이 충분하게 이루어진 후에 데모그래픽한 기준으로 데이터를 세분화하여 분석해야합니다. 이런 과정을 위해서 가장 도움이 되는 것이 리스닝마인드라고 자신있게 말씀드릴 수 있습니다.
자사 브랜드에 속하는 몇가지 상품이나 서비스의 키워드 몇 가지를 확인하는 작업이라면 어려울 것이 없지만, 소비자의 선택이 겹칠 수 있는 경쟁 브랜드와 대체 상품이나 서비스가 존재할 경우 연관된 키워드를 충분하게 수집하는 작업은 결코 쉽지 않습니다. 사실 이렇게 충분한 양의 키워드를 수집해야만 유사한 의도를 지닌 혹은 동일 브랜드, 동일 제조사 등의 범주로 키워드를 묶어 이들을 레이블링하고 여기서 더 깊이 있는 분석을 할 수 있습니다. 다시 한번 강조합니다만 대상으로 삼은 영역과 관련한 충분한 전체 검색어를 확보하고 이들의 충분한 기간의 월별 검색량을 확보해야만 의미 있는 인사이트를 도출할 수 있습니다.
일단 오늘 글에서는 데모그래픽 정보를 기준으로 검색 데이터를 시각화 하는 것에 집중하여 설명을 이어가겠습니다.
성별 및 연령 데이터 수집 정보와 시각화 구현
예를 들어, 2024년 3월부터 ~ 2025년 2월까지 1년을 기준으로, 검색어에 대해 매월 데이터를 수집하게 되면 다음과 같은 가공 데이터를 확보 가능합니다. 이 가공된 데이터를 통해 연령과 성별에 따른 다양한 검색 데이터를 체계적으로 수집하여 분석할 수 있습니다. 리스닝마인드는 한국 데이터를 기준으로 할 때 조사시점에서 과거 2년의 검색 볼륨 데이터를 확보할 수 있습니다. 일본 데이터를 기준으로 할 때에는 과거 4년의 검색 볼륨 데이터를 확보할 수 있습니다.
리스닝마인드에서 성별 및 연령 데이터를 분석하고 시각화하기 위해 수집할 수 있는 정보는 다음과 같습니다.
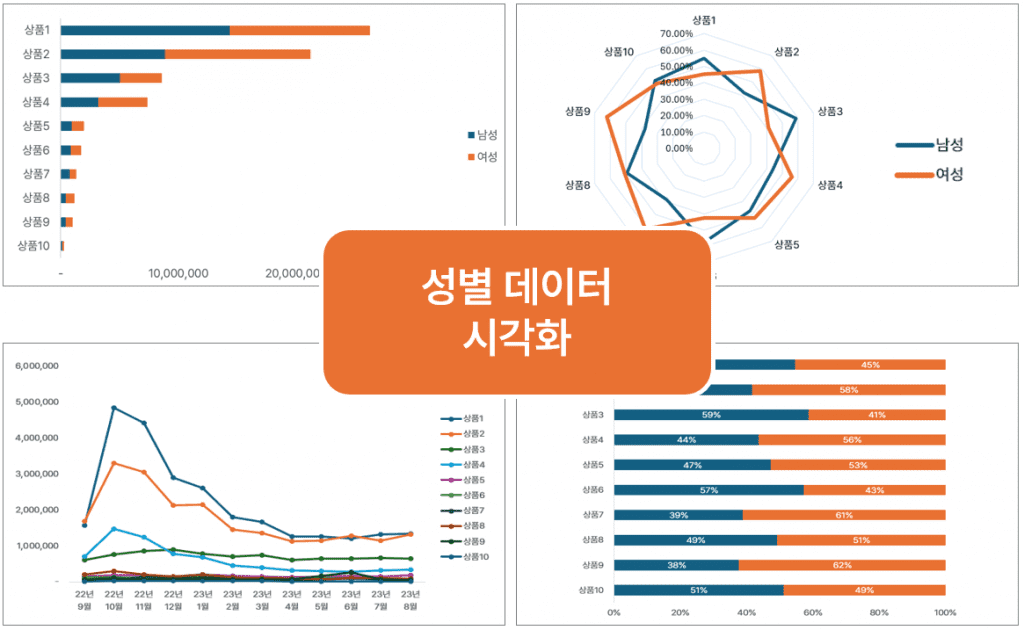
- 성별 데이터
- 남성과 여성 검색 이용자의 12개월 검색 데이터
- 남녀 1년 누적 검색량 현황
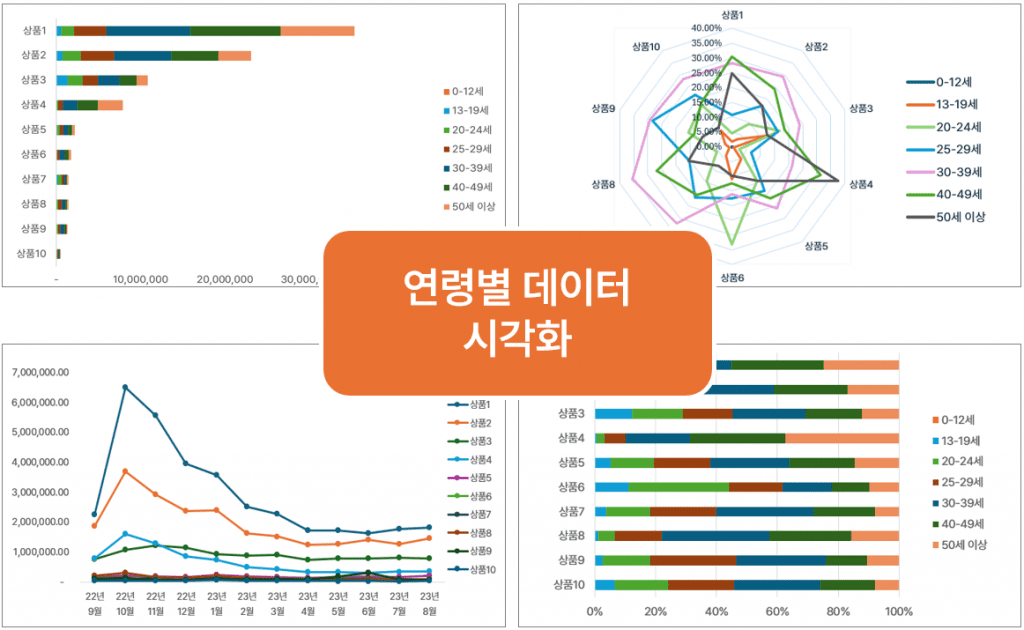
- 연령별 데이터
- 0-12세, 13-19세, 20-24세, 25-29세, 30-39세, 40-49세, 50세 이상의 각 연령대별 12개월 검색 데이터
- 연령대별 1년 누적 검색량 현황
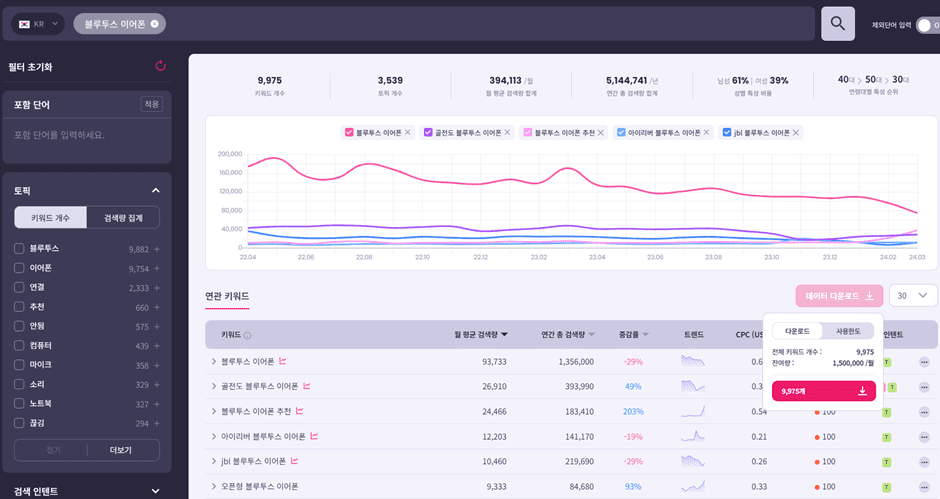
리스닝마인드를 통해 키워드 정보 다운로드하기
인텐트파인더에서라면 확인하고자 하는 시드 키워드를 입력하고 검색을 하면 관련된 모든 키워드가 리스트에 나타납니다. 이 전체를 받고자 한다면 그래프 우하단에 있는 다운로드 버튼을 눌러 파일을 다운로드 합니다. 단 전체가 아닐 특정 토픽이나 필터로 걸러낸 데이터만 다운로드 받고 자 할 때에는 인텐트 파인더 좌측에 있는 필터를 선택한 후에 다운로드 버튼을 눌러 수집하고자 하는 데이터를 다운로드 받습니다.
다운로드한 엑셀 데이터 정보 확인하기
리스닝마인드의 검색 데이터를 엑셀포멧으로 다운로드하게 되면 다음과 같은 정보를 얻을 수 있는데요. 가장 왼쪽 컬럼에 검색 키워드가 오고 오른쪽으로 다양한 컬럼이 위치합니다. 이 컬럼 중에는 각 키워드의 검색량에 있어서 남성과 여성의 구성비, 12세 이하에서 50세 이상까지 7개의 그룹으로 구분한 연령별 검색 비율 정보를 제공하고 있습니다.
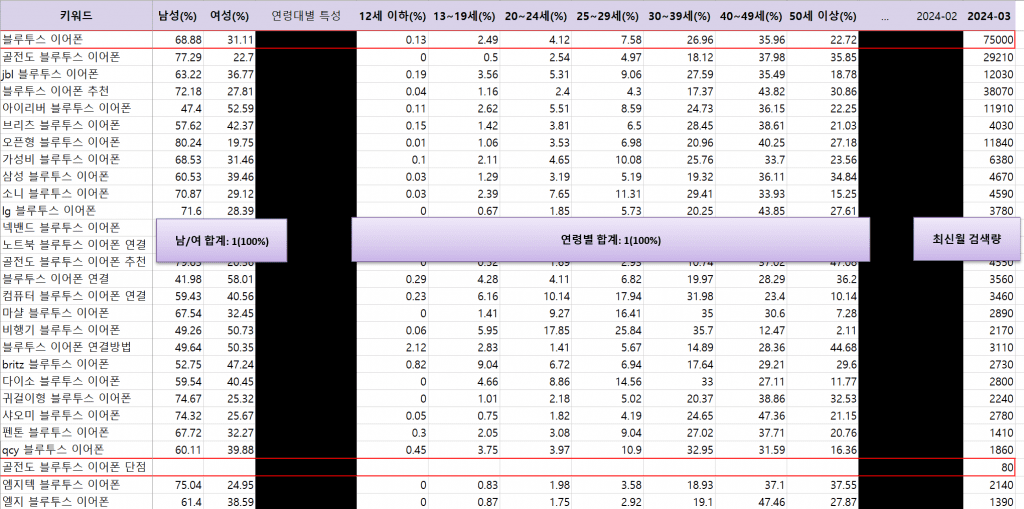
각 키워드의 연령 및 성별 정보를 확인할 때 2가지 케이스가 존재합니다.
예를 들어, 이미지에서 키워드 “블루투스 이어폰” 은 모든 비율 정보를 포함하고 있지만 “골전도 블루투스 이어폰 단점” 키워드는 성별 및 연령별 데이터를 제공하지 않고 빈 값으로 표시되고 있습니다.
- 성별 및 연령별 데이터를 제공하는 경우 – 예시: 블루투스 이어폰
성별 데이터: 여성, 남성 비율의 합이 1에 수렴 (합계 비율 100%)
연령별 데이터: 0~50세 이상 비율의 합이 1에 수렴 (합계 비율 100%) - 성별 및 연령별 데이터를 미제공하는 경우 – 예시: 골전도 블루투스 이어폰 단점
24년 3월 검색량이 0이거나, 네이버에서 해당 데이터를 제공하지 않는 경우
아래 키워드 중에서 골전도 블루투스 이어폰의 경우 24년 3월 데이터를 제공하고 있는 것을 확인할 수 있습니다. 이 경우는 구글의 검색량만 제공하고 있는 경우이라고 추측해볼 수 있겠네요
두번째 경우는 검색량은 존재하지만, 데모그래픽 정보가 존재하지 않기 때문에 세부 검색량을 구할 수 없기 때문에 별도 표시하여 관리합니다.
성별 및 연령별 유효 검색량 구하기
성별 및 연령 비율을 제공하는 경우에 대해서만 유효한 검색량을 구해보겠습니다.
각 비율 값을 검색량으로 변환하는 작업은 =개별 키워드 월 검색량*해당 항목의 비율/100으로 표시하여 칼럼을 생성합니다.
예를 들어 “블루투스 이어폰“의 제공된 성별 및 연령별 비율에 따라 2024년 3월 검색량을 각각 구합니다.
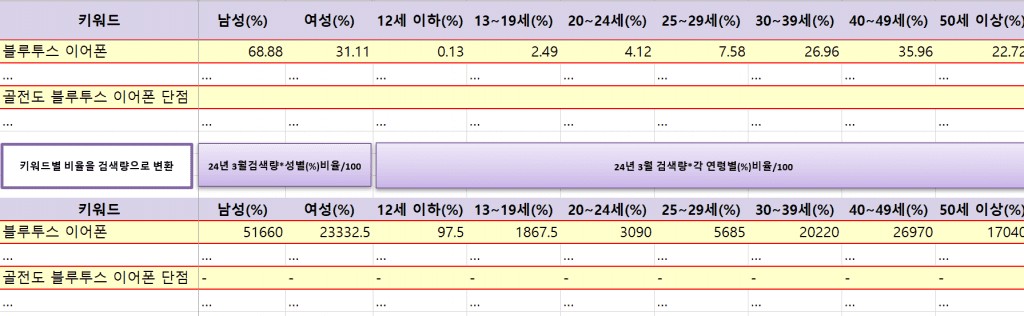
이렇게 확인하고자 하는 키워드 모두 각 항목의 검색량을 도출했다면, 24년 3월달에 각 성별과 연령별 데이터를 월별로 정기적으로 확보할 수 있습니다.
이와 같이 각 성별 및 연령별 총 검색량의 누적치(sum)를 확인 가능합니다.
키워드 리서치 : 데이터 라벨링 작업
데이터 라벨링 단계에서는 대규모 키워드 리스트에 대해 정제된 검색 데이터에 의미 있는 태그나 레이블을 부여하는 작업이 이루어집니다. 이 과정에서는 키워드의 의도와 맥락을 이해하고, 관련된 키워드들을 그룹화하여 범주를 형성합니다.
이렇게 생성된 범주를 통해 보다 큰 검색량을 확보하고, 이를 연령 및 성별로 세분화하여 분석할 수 있게 됩니다.
따라서, 성별 및 연령 데이터를 분석하고 시각화하기 위한 첫 단계는 키워드 라벨링 작업이라고 볼 수 있습니다. 이 작업을 통해 키워드를 의도와 맥락에 따라 분류하고, 대규모 데이터를 정제하여 의미 있는 인사이트를 얻을 수 있습니다. 이를 바탕으로 연령별, 성별별로 세분화된 검색 데이터를 분석하여, 보다 구체적이고 유용한 정보를 도출할 수 있습니다.
어센트코리아는 이러한 데이터 라벨링 작업을 통해 ‘엔터프라이즈’ 서비스를 제공합니다.
왜 ‘엔터프라이즈’ 서비스를 선택해야 할까요?
- 맞춤형 분석: 연령 및 성별로 세분화된 데이터로 고객의 다양한 요구를 충족시킬 수 있습니다.정확한 인사이트: 대규모 데이터를 정제하고 라벨링하여 보다 정확하고 신뢰성 있는 인사이트를 제공합니다.
- 비즈니스 성장 지원: 고객이 데이터를 효과적으로 활용할 수 있도록 도와 맞춤형 전략 수립을 지원합니다.엔터프라이즈’ 서비스를 통해, 귀사는 고객의 검색 패턴을 정확히 파악하고, 이를 기반으로 한 전략적 의사결정을 내릴 수 있습니다.
이러한 작업을 통해서 라벨링한 키워드 데이터 정보를 각 데모그래픽 세그먼트대로 시각화를 구현하여 다채로운 검색 데이터 확인이 가능합니다.
이렇게 검색 데이터를 라벨링하고, 월별로 정기적인 성별 및 연령 데이터를 다운로드하게 되면
방대한 양의 폴더를 정리하여 관리가 필요합니다.